👋 Hello, I'm César García Cabeza
About Me
With a foundation in Computer Software Engineering, sparked by a deep love for video games, I initially embarked on a journey in software development. However, during the transformative deep learning boom, my career trajectory shifted toward data science and artificial intelligence. This new direction inspired me to pursue two Master's degrees—one in Artificial Intelligence and another in Cloud Data Science & Data Engineering. My academic curiosity also led me to begin a PhD in Information Technologies, where I focused on leveraging AI techniques to automate systematic literature reviews. Despite the allure of academia, I ultimately chose to return to industry to apply my skills in real-world, practical settings.
Today, I work as a Data Scientist at a leading SEM agency, where I harness the power of data to drive impactful, data-informed marketing strategies. My passion lies at the intersection of software engineering and data science/engineering, where I explore how these fields can revolutionize industries.
Looking ahead, I aspire to lead a data team, fostering growth and collaboration to achieve collective success. As a versatile and curious professional, I continually seek out new technologies and challenges, embodying a T-shaped skill set that bridges multiple domains. My relentless drive to learn and achieve means that when I set my sights on a goal, I don't stop until it's accomplished.
In addition to my full-time role, I'm actively seeking side projects where I can apply my technical knowledge and expertise. If you have a project that could benefit from my skills in data science, AI, or software engineering, I'd love to hear about it. Feel free to use the scheduling tool in the contact section to book a time for us to discuss potential collaborations.
Technical Skills
Soft Skills
Experience
Data Scientist
Gauss & Neumann-
Leverage data science techniques to extract valuable insights, enabling the formulation of data-informed marketing strategies that significantly improve campaign performance
-
Create and maintain ETL pipelines with Apache Airflow, ensuring seamless data integration and flow across multiple platforms and processes (APIs, BigQuery, S3, GCS, etc)
-
Design and maintain dynamic dashboards using Apache Superset, Looker Studio, and Google Sheets for internal and external reporting
-
Design and conduct experimentations using both frequentist and Bayesian methodologies, including A/B tests, pre/post tests, and geo-split tests. Utilize causal analysis to drive continuous improvements in campaign outcomes
-
Develop & optimize internal Python libraries to enhance operational efficiency
-
Use APIs from platforms like Google Ads, Bing Ads, and Google Analytics to continuously monitor and optimize campaign performance
-
Daily email reporting and weekly meetings with key stakeholders, including the CMO and the VP of Marketing and Analytics, ensuring alignment on goals and strategies
Tech stack: Python, Airflow, SQL, Docker, BigQuery & GCP, Google Ads & Google Analytics APIs
Software Engineer Intern
Dail SoftwareDuring my master's degree, I completed an internship at Dail Software while preparing my master's thesis. This role provided me with hands-on experience in Natural Language Processing (NLP) techniques and the development of chatbots and recommender systems for various clients.
-
Applied NLP techniques to real-world projects
-
Developed chatbots and recommender systems tailored to client needs
-
Gained proficiency in Python, Rasa, Gensim, and NLTK
Tech stack: Python, Rasa, Gensim, NLTK, Docker
Research Intern
Biomedichal Informatics Group (Polytechnic University of Madrid)I conducted an internship during the first month of my master's degree within the Biomedical Research Group. This experience provided valuable insights into medical data integration and helped shape my career interests.
-
Learned about medical data integration tools using terminologies such as LOINC, ICD-10, and SNOMED
-
Gained exposure to the complexities of biomedical data
-
Realized a stronger interest in natural language processing, leading to a career shift
Tech stack: Python, Tableau
Undergraduate Research Intern
UNIMODE Research Group (University of Oviedo)During my undergraduate degree, I completed a research-focused internship in collaboration with two professors from the Computability and Artificial Intelligence department. This role set the foundation for my Final Degree Project.
-
Conducted a comprehensive bibliography review about partially ordered sets
-
Analyzed and optimized various algorithms
-
Developed new algorithms based on different techniques including sorting algorithms, simulated annealing, and linear programming
-
Applied these tasks to the aggregation of partially ordered sets
Projects
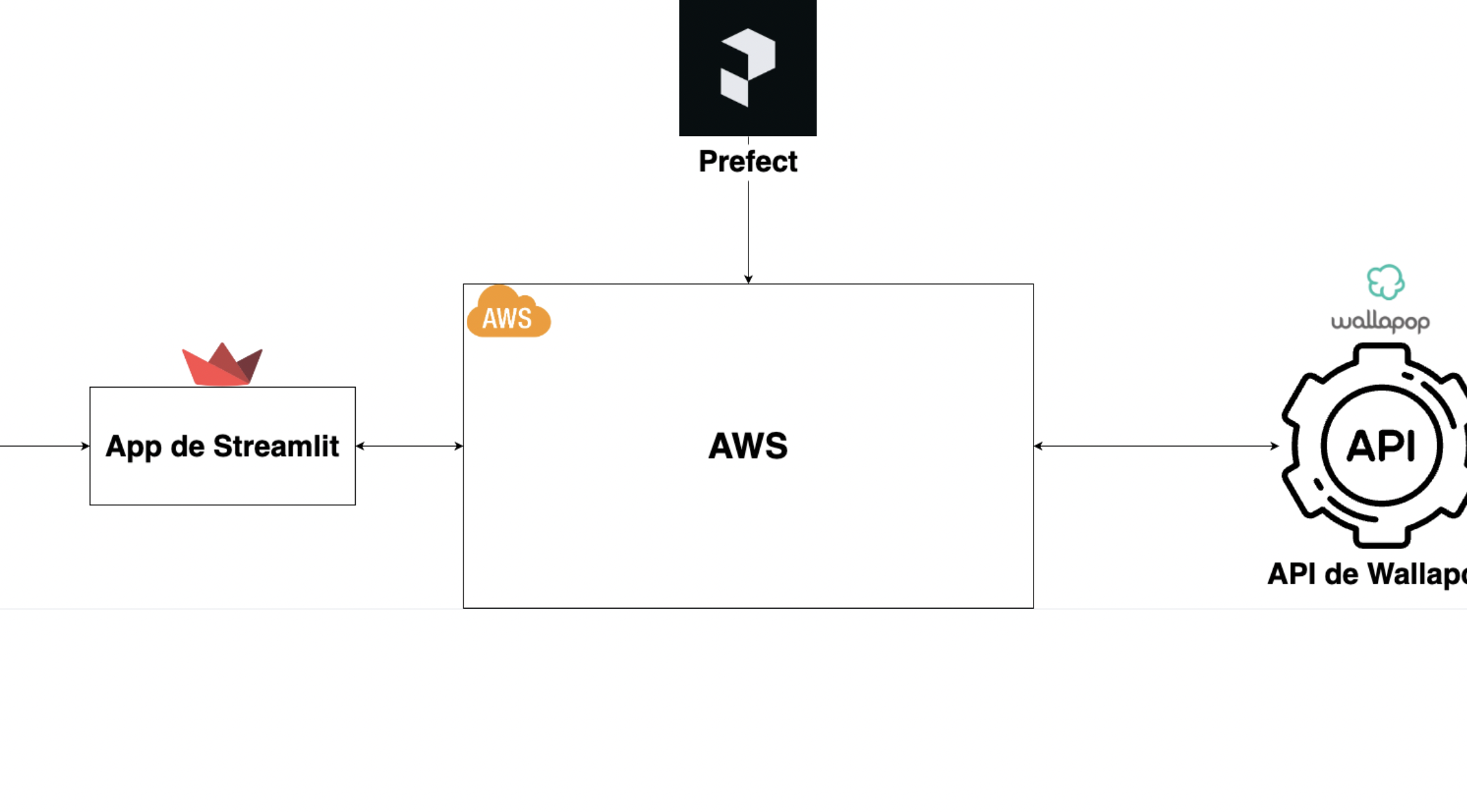
Wallapop Data Extraction & Data Visualization Pipeline
Developed a scalable, serverless data pipeline and visualization app using AWS, Prefect, and Streamlit to extract and analyze data from the Wallapop API. Automated infrastructure deployment with Terraform and integrated CI/CD pipelines with GitHub Actions for efficient updates and management.

Assessing ChatGPT's Performance in the Spanish MIR Exam Using Python Automation
This project evaluates ChatGPT's ability to pass the Spanish MIR exam by automating exam reading with Python and integrating the OpenAI API with Streamlit. The goal is to compare its performance with that of human candidates and explore the potential of AI in medical education.
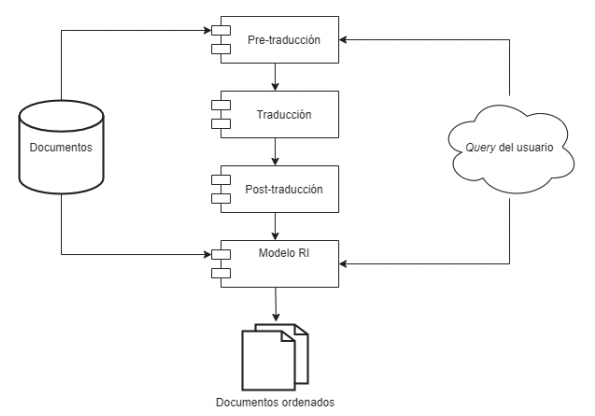
Multilingual Document Retrieval Using Universal Networking Language as an Interlingua
This project analyzes existing methods for addressing multilinguality in document retrieval systems, proposing a novel model that leverages the Universal Networking Language (UNL) as an interlingua. Implemented using Python, the model demonstrates effective results in cross-lingual searches from English to Spanish, provided high-quality dictionaries are used.
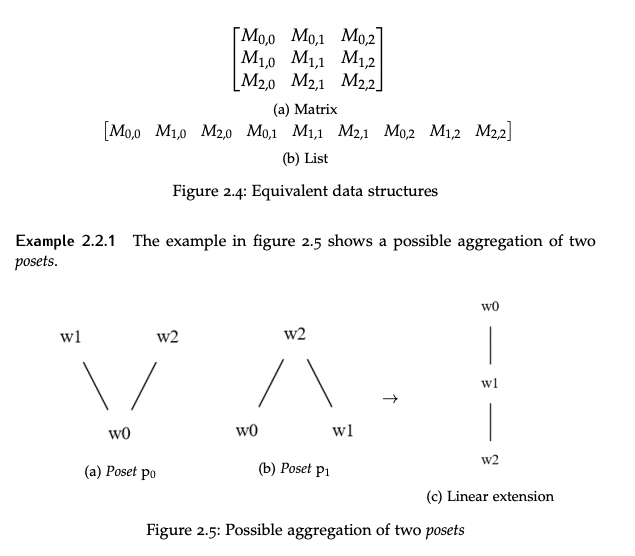
Development of Aggregation Methods of Partially Ordered Sets
Partially ordered sets are collections in which elements are not totally ordered, introducing uncertainty in their structure. This project focuses on developing new aggregation algorithms for these sets, implemented in C#. The algorithms aim to improve the processing and interpretation of partially ordered data, contributing to advancements in computational methods for uncertain data structures.